Beyond state-of-the-art accuracy by fostering ensemble generalization
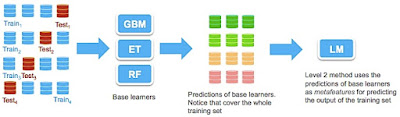
Sometimes practitioners are forced to go beyond the standard methods in order to gain more accuracy with their models. If one analyzes the problem of rocketing accuracy, ensembling is a good starting point. However, the trick lies in getting enough generalization from feature space. In this regard, ensemble generalization--do not confuse with classic or "standard" ensemble methods such as Random Forest or Gradient Boosting-- is the right path to follow, however complex. The idea is to combine predictions from "base learners" to train a second stage regressor, using these predictions as metafeatures. The trick is to use a J-fold cross-validation scheme and use always the same data partitions and seed. This kind of ensemble is often called stacking --as we "stack" layers of classifiers. Let’s do an example: suppose that we have three base learners: GBM, ET, and RF. Then assume we have a LM as level 2 learner. First we divide the training data into ...